Indexing XML documents
We designed an indexing structure for
XML documents, called the Collection Index (C-Index),
that supports an effective
and efficient processing of complex approximate queries on XML data. The C-Index
aims to reduce the complexity of finding approximate query patterns, avoiding
the sequential examination of all documents in an XML collection.
The C-Index is based on
an intensional view of the data, similarly in spirit with traditional
database modeling where data is separate from the schema. The C-Index is a
concise representation of the structure of all the documents in a collection, in
that each document can be mapped exactly in one part of the C-Index. The
structure we propose resembles a DataGuide, extending the query capabilities to
retrieve approximate answers.
Consider Figure 4:
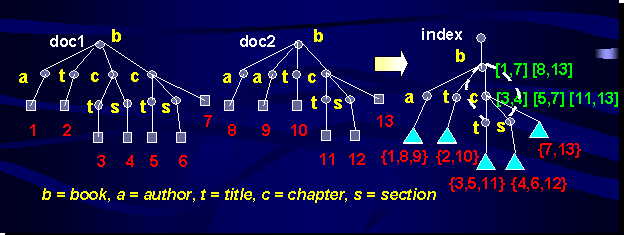
Figure 4: Sample Collection
Index obtained after indexing documents doc1 and doc2.
The C-Index is an
extended template for the structure of a set of XML documents, and it
provides a skeleton in accordance with the structural relationships occurring in
the documents.
The C-Index is created
incrementally, inserting one document at a time, according to the following
steps:
- All data leaves are globally
numbered with increasing integer values from left to right. This numbering
scheme allows for uniquely identifying each data leaf in the C-Index. Two
sample document trees are shown on the left side of Fig. 4: Squares denote
data leaves, and tree nodes are marked by circles.
- Path instances in the documents are
assigned to equivalence classes according to the sequence of node
labels they are made of. Only one path per class is inserted in the C-Index.
The paths in the C-Index possibly share common prefixes.
- Each C-Index (sub)path starting
from the root references the set of data leaves referred by the document paths
it has been derived from. Thus, each C-Index (sub)path defines a semantic
context where the underneath data leaves are referenced according to IR access
structures local to the (sub)path, e.g. B+tree on leaf numbers, and inverted
lists on terms. These access structures are depicted by triangles in Fig. 4.
We call each structure a Value-Index.
- Each inner node n keeps a
pair of integer values [lmin,lmax] for each
occurrence of the (sub)path from C-Index root to n occurring in
the data tree. Each range denotes the set of data leaves underneath the
instance data node, such that lmin is the lowest leaf number
and, lmax is the highest one, respectively. Each sequence of
ranges is locally ordered by increasing values of lmin, and
ranges are disjoint.
- Each inner node references its
descendants in the tree. We take advantage of this additional information to
efficiently perform approximate retrieval on structure. In Fig. 4 arcs
depicted by dashed lines denote ancestorship between nodes, parentship is
implicitly expressed by solid arcs, and, for simplicity, references to
descendants of C-Index root are omitted.
Insertion of documents is an
incremental process that does not require the C-Index to be restructured.
There is no need for a priori knowledge of the schema of the data, since the
path we encode are extracted from the data itself. Actually the C-Index is more properly a single rooted DAG, because of the links to the
descendants of each node.
Query processing with the C-Index is performed in 2 steps:
- Top-down navigation for selecting
relevant contexts, solving the Approximate Tree Embedding Problem. The
navigation is guided by the preorder visit of the query tree.
- Each query node is attached a set
of contextual approximate matches with nodes in the C-Index.
- Recursively, each matched C-Index
node is taken as relevant context for the rest of the query path.
- Bottom-up construction of results,
exploting the information contained in the range lists of each matched node
- Each query leaf q is
assigned a (set of) data stream path, each denoting a different
structural approximation for the query path leading to q.
- Each data stream path is
instantiated to a data stream, i.e. the set of relevant data leaves
returned by the corresponding Value-Index.
- The bottom-up navigation of the
C-Index is guided by the postorder visit of the extended query tree.
- Each node n is assigned a
list of contextual ranges as follows:
- ranges for a query leaf are its
data streams
- for inner node n, collect
contextual ranges from children
- get ranges for each contextual
match of n in the C-Index and check range inclusion with
children's ranges. Recall that:
- each range r denotes a
(sub)document instance di
- two data leaves belong to the
same (sub)document instance di if their id's belong to the range r
that identified di
- 2 sub(document) instances di
and dk belong to the same (sub)document d if
their ranges ri and rk are both
included in the range r of d
- assign the result as the list of
contextual ranges for n
- Contextual ranges assigned to the
query root identify (sub)document instances that satisfy the query.
From experimental results, the size of
the
C-Index scales linearly with the number of elements in the
collection, since a range is kept for each (sub)document instance. The size of
the C-Index tree, "pure" structure and links to descendants, is negligible
and stable (depending on the heterogeneity of the collection). For instance, for
a collection of about 800 Mb, with 6200K elements, the C-Index tree takes
14Kb and the range lists about 120 Mb.
As to query response time, the
performance of the C-Index depends on the selectivity of the
query pattern, since the main cost is given by the check for range inclusion,
and it increases linearly with the number of ranges to be checked. As a matter
of fact, the cost of computing the Approximate Tree Embedding on the
C-Index is negligible, due to the low size of the tree.
Finally, the C-Index is
suitable to the application of different navigation stategies, according to the
user needs. More details can be found in [CP03].