Motivation
The increasing availability of large digital libraries is raising XML to be the new standard for the representation of textual data. This implies that several efforts have been recently devoted to the development of efficient and effective techniques for the management of XML data.
The presence of nested tags inside XML documents leads to the necessity of managing structural information. When querying XML data, the user is allowed to express predicates to specify the context where data is to be retrieved. For instance, the user might want to retrieve:
CDs authored by a singer whose lastname is John and containing a song having the word love in the title
Of course the user is not interested in retrieving whatsoever is containing the keywords "John" and "love". This implies that both a structural match for the context (lastname of singer, title of song in CD) and a (traditional IR) semantic match for the content (the keywords "John" and "love") have to be found.
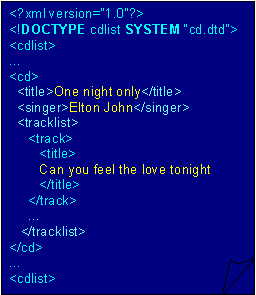
Consider document Doc1 in Figure 1:
Figure 1: Sample XML document
Doc1 contains a relevant answer to the query above, although some clashes are present:
The example shows that, in absence of knowledge of structural relationships among data, Boolean query conditions may produce no answers. Because of the heterogeneity of large collections of documents, querying blindly XML data requires a great deal of flexibility not to fall into the trap of "empty results", often caused by too strict constraints. To overcome these cases, approximate matching techniques are acknowledged to provide powerful solutions.
Goals
In the presence of semantic and structural approximations, results should be ranked according to their similarity to the user's query. Most methods produce ranking values that do not provide information on the query rate satisfied by an answer. For instance, given a query, it is not possible to realize if a document is assigned a low score because of an approximate yet complete match, or because of a partial yet exact match of query requirements.
We defined a ranking measure that shows the rate of query satisfied, effectively captures both semantic and structural relevance of results, keep these values separate, and allows the user to possibly weigh more one value than the others. Further, the ranking measure proposed captures the relevance given by multiple occurrences of the query pattern in the data retrieved.
As to efficiency, it is evident that sequential processing of documents in large digital libraries is not affordable as to response time. We designed an indexing structure to execute efficiently approximate complex queries on XML documents.