Ranking
Relaxations on both semantics and structure are expected to affect the score of results. Ranking approaches based on the number of query transformations, such as the Tree Edit Distance, appear to be too coarse-grained.
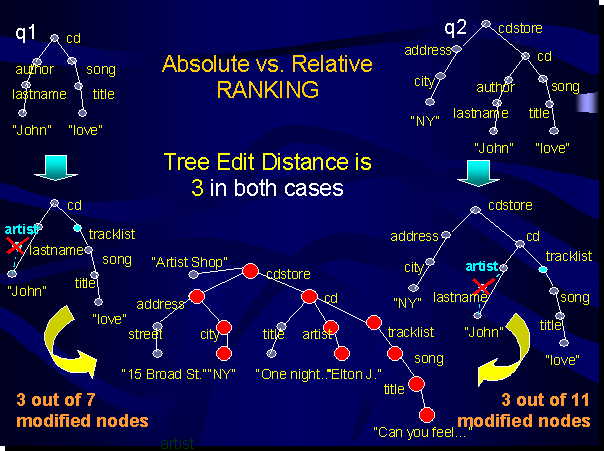
Consider Figure 3:
Figure 3: Query q1 and q2 require the same transformations to match the document.
Assuming a Tree Edit Distance approach, the satisfiability of the two queries would
have been considered equivalent. Indeed, although we are comparing different queries,
and not different results, it clearly appears that the score they have been assigned
does not provide any information on the rate of query satisfied by the document.
Query q1 is indeed satisfied after modification of 3 out of 7 nodes (high percentage),
whereas query q2 is satisfied after modification of 3 out of 11 nodes (low percentage).
This emphasizes that the current document satisfies better query q2 than query q1,
and also provides information on the quality of results.
Thus, an effective ranking function should take into account the query rate satisfied by an answer, i.e. the completeness of the anwer, so as to tune better its relevance.
Moreover, the use of wildcards flattens the score of results, which are considered relevant no matter the grade of sparseness of the data retrieved. Thus, a further key element to be considered is the cohesion of the aswers.
We propose a ranking function, called SATES (Scored Approximate Tree Embedding Set function), that captures all these features:
Given a query tree tq , a document tree td , and an approximate tree embedding e[tq,td] of tq in td , SATES is a function that returns a score s in S=[0,1] such that, with respect to e, s is obtained as a combination of the following components:
Then, s = F(s1,s2,s3,s4,s5) is given by the combination of the above components, with F (possibly weighable) combine function. s states the overall similarity score of the embedding e.