(Semantic-based HIerarchical Automatic Tagging of videos by Segmentation using cUts)
System
The dramatic growth of video content over modern media channels (such as the Internet and mobile phone platforms) directs the interest of media broad-casters towards the topics of video retrieval and content browsing. Several video retrieval systems benefit from the use of semantic indexing based on content, since it allows an intuitive categorization of videos. However, indexing is usually performed through manual annotation, thus introducing potential problems such as ambiguity, lack of information, and non-relevance of index terms.
SHIATSU is a complete software system for video retrieval which is based on the (semi-)automatic hierarchical semantic annotation of videos exploiting the analysis of visual content (possibly also using audio content); videos can then be searched by means of attached tags and/or visual features.
The SHIATSU approach first divides a video into sequences of visually coherent frames (or shots): each sequence, being homogeneous in content, could then be automatically labeled using the previously described techniques. Finally, tags associated with frames sequences can be, in a way, propagated to the whole video, thus obtaining a hierarchical technique for video tagging.
Segmentation
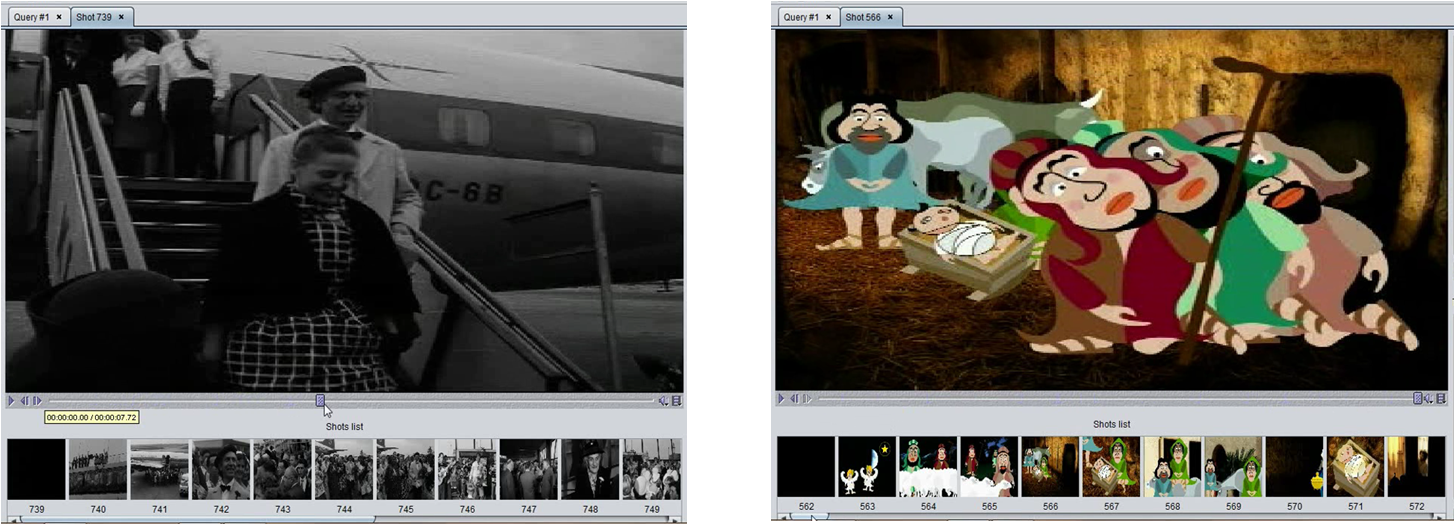
The SHIATSU shot detection module exploits color histograms and object edges to compare consecutive frames by applying two different distance metrics: this is because usually a shot transition produces a change in both the color and the texture structure of the frames. A double dynamic threshold system is then used in order to take into account possible dissimilarities in the content of different video types.
To give a concrete example, the following figures show the results of the segmentation process when applied to two different contexts: black&white movies (left) and cartoons (right).
Annotation
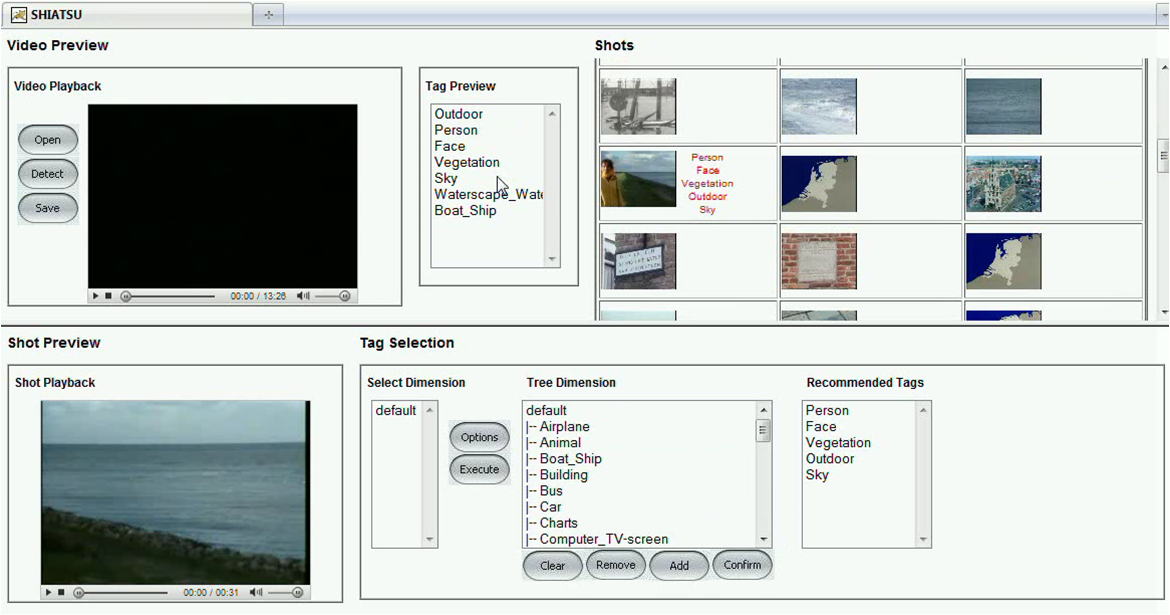
The annotation of shots (and videos) in SHIATSU is based on the principle that objects that share a similar visual content also have the same semantic content, thus similar objects should be tagged using the same labels.
This paradigm, that has been proficiently used for the automatic annotation of images, is exploited in SHIATSU for automatically suggesting to the user labels at the shot level. For this, the annotation processor retrieves the tags assigned to shots containing frames that are most visually similar to frames contained in the shot currently under examination. This is performed by automatically extracting from frames a number of visual features that are compared to visual features (a metric index allows to efficiently retrieve only the most relevant features for each frame).
In the following figure, an example of shot annotation is depicted (bottom) together with its persistent propagation at the shot and video levels (top).
Retrieval
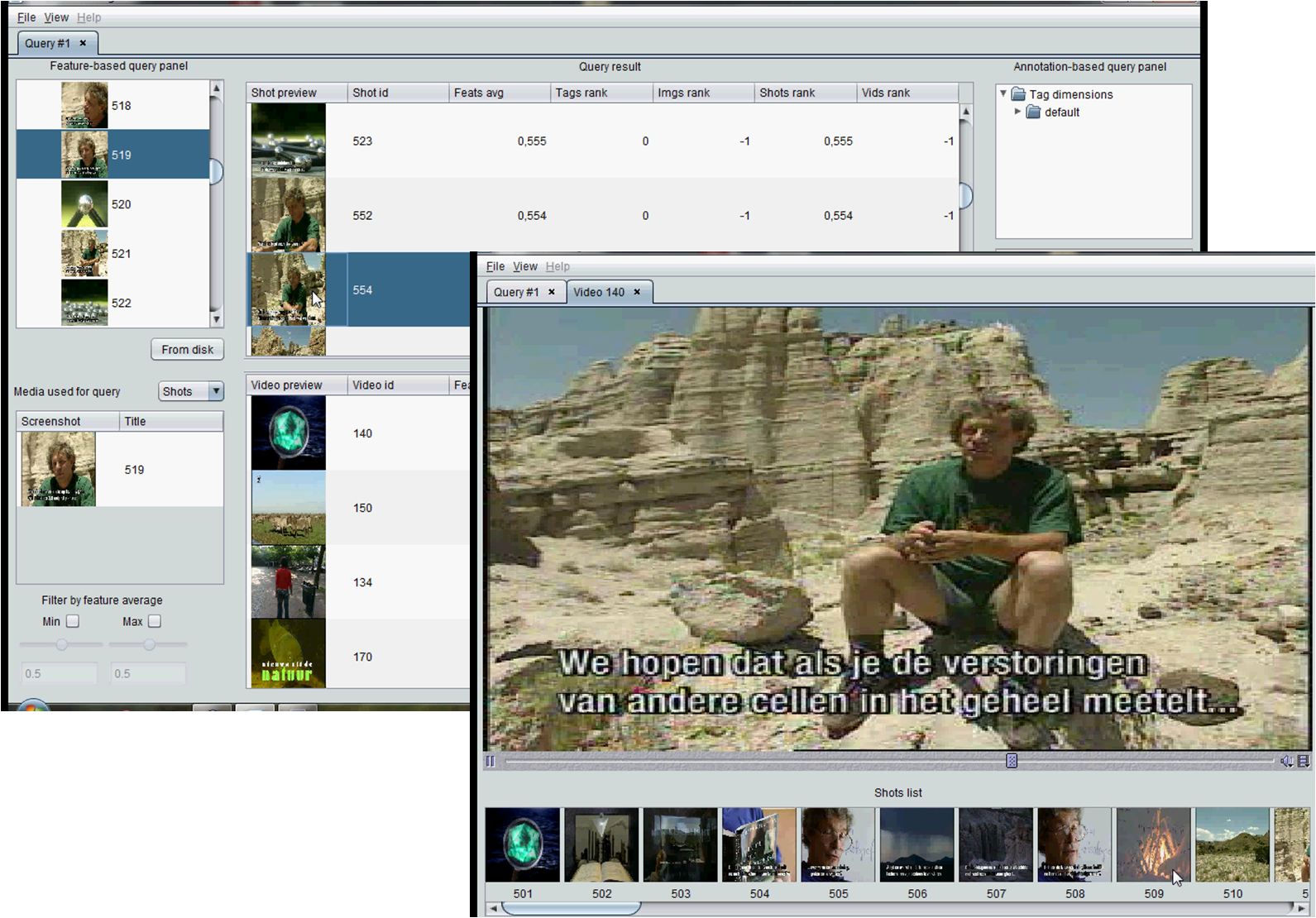
SHIATSU manages different user requests so as to efficiently return the videos/shots/key-frames of interest. Query results can be retrieved according to one of three available query paradigms: keyword-based (KS), feature-based (FS), and keyword&feature-based (KFS) searches.
The KS paradigm is the easiest and most popular query modality, used by traditional search engines, where the user enters a set of keywords as query semantic concepts. According to this query paradigm, the result list only includes those videos/shots containing at least one tag among those submitted by the user. The list of returned objects is sorted according to the number of tags that co-occur in each video/shot.
On the other hand, FS queries exploit content features to retrieve those videos/shots that are most visually similar to a given video/shot.
In the following, an example of FS shot query is shown (left), together with the set of the most similar shots and corresponding videos (right). The playing interface of the video of the selected shot is also depicted by focusing on the part of interest (bottom right).